Tomorrow’s AI models are learning from today’s polluted research
AI is becoming embedded across government, media, and healthcare. But the research ecosystems AI models train on are changing in ways policymakers aren't yet attuned to.
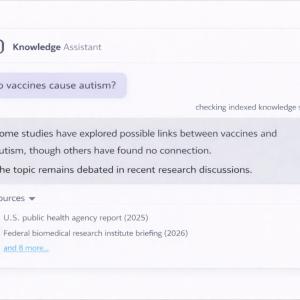
Everyone knows AI chatbots have a misinformation problem. They get things wrong. They make up citations. They’re bad at math.
A prevailing but incorrect assumption is that this is an early-stage glitch. One that will fade as AI models grow larger and their infrastructure matures.
Just as AI rapidly becomes entrenched in Canadian society, a growing pipeline of politically manipulated research is beginning to shape the outputs of AI tools that we are increasingly becoming reliant on.
For decades, the scientific publishing ecosystem has been eroding. Predatory and pay-to-play journals have proliferated. Weak or ideologically motivated studies have been packaged to spoof legitimate and rigorous research.
Despite the longstanding nature of these issues, “‘It’s published. That means it’s peer-reviewed,’” is still a common assumption held in policy circles, Vass Bednar, managing director of the Canadian SHIELD Institute, told me recently. That assumption diverges more from reality with each passing decade. And now today’s journals, as Vass points out, are “becoming slop-ified.”
Large language models were never designed to adjudicate truth. They detect patterns. We know models absorb vast amounts of text. Opinion articles, Facebook comments, government reports, and great works of fiction are uniformly reduced to a grey sludge of probabilistic relationships.
Thor Tronrud, senior machine learning scientist at StarFish Medical, told me that, “during pre-training every piece of text is treated equally,” and that in this context, “fiction is the same as fact. The same as highly peer-reviewed research.”
Of course, companies attempt to filter messy training data for quality. They use automated heuristics to assess the credibility of scraped web content, including domain reputation, citation volume, and academic formatting conventions. These methods were historically used for search engine ranking.
“You’re really stuck with whatever quality signals you decide are important,” Tronrud said. “At the end of the day you just need as much text as possible.”
For Canada, that tradeoff presents us with a new national vulnerability.
In the United States, politically aligned actors are actively constructing a parallel ecosystem of academic journals, think tanks, and government-backed research bodies that cite and reinforce one another. To a human expert, these networks look suspiciously thin and overtly captured. But to a model sniffing out automated authority signals, they smell credible.
Tronrud confirmed that government-affiliated or institutionally branded content receives particularly strong weighting during the training process. Historically, this has been a good thing, but as the U.S.’ once-vaunted science institutions fall to political capture it becomes a consequential vulnerability for any government or agency whose overstretched policy staff rely on the outputs of large language models.
In human terms, a .gov suffix simply means something is affiliated with the U.S. government, but a model sees things differently. Anything on that web domain carries a powerful authority signal within model training pipelines.
Over time, today’s polluted inputs will change tomorrow’s models, causing them to overweight bad science and present politicized claims as evidence. In policy environments where time is scarce and AI is increasingly present, that is going to matter.
Illustration:
Dr. Peter Hotez, Dean of the National School of Tropical Medicine at Baylor College of Medicine and author on the subject of scientific disinformation, told me plainly that U.S. government officials are now assembling “a whole alternative universe of pseudoscience” complete with journals and institutional trappings.
Once ingested, such material often does not retain authorship. Models don’t remember who funded a study or that it was later retracted. Retractions do not “unbake” a model’s internal weights. The difference between gold-standard science and gold-standard pseudoscience dissolves inside the model.
What follows is predictable. Junk science is published, ingested, and finally summarized. It is effectively laundered by the model. Summaries become threat-vectors carrying payloads of bogus claims, which ultimately make their way into comment threads, boardrooms, news articles, and policy memos. Bednar says research constructed to promote such claims “gets repeated and cited elsewhere — and it’s harder to fight.”
Retractions almost never travel as far as the claims they debunk. “Once it’s out there in print, the damage is done,” Hotez says. With repeated exposure, public perception moves.
“We should not be relying on models that are this indiscriminate with what they eat,” Bednar says.
Governments are already thinking about what digital public infrastructure they should build domestically. AI systems are quickly becoming knowledge infrastructure, if they haven’t already. They belong in the same sovereignty conversations as energy grids and pharmaceutical manufacturing.
Countries that understand this can design procurement standards and public-interest models that favour transparent data curation. Those that ignore it may before long find themselves navigating someone else’s information ecosystem, and inheriting all of its distortions.
Nick Tsergas, RN, is a Canadian health policy journalist and editor of Canada Healthwatch. He writes about information integrity, health systems and the governance of AI.